|


Platinum
Tutorial 9: Step 3 Create a SVM Classifier
Create a SVM Classifier
1. Select the Khan_training_data item in the Experiments navigator. The item is highlighted.
2. Select Create SVM Classifier from the Predict menu, or right-click the item and select Create SVM Classifier from the shortcut menu. The Create SVM Classifier parameters dialog is displayed.
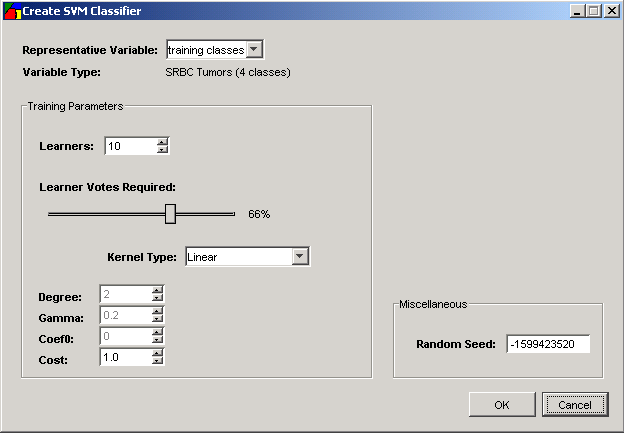
3. Set dialog parameters.
|
Parameter |
Setting |
|
Representative Variable |
Training classes |
|
Kernel Type |
Linear: u*v Polynomial: (gamma*u*v + coef0)^degree Radial basis function: exp(-gamma*|u-v|^2) Default: Linear |
|
Degree for polynomial kernel |
Default 2 |
|
Gamma |
Default 0.2. A good heuristic is 1/the number of classes. |
|
Coef0 for poly |
Default 0.0 |
|
Cost |
Default 1.0 |
|
Epsilon |
Default 2 |
|
Learners |
Default 10 |
|
Miscellaneous: Random Seed |
999 (See Note below) |
4. Accept the default values for the all other parameters and click OK. The Create SVM Classifier operation is performed, and a new item (SVM: training classes|2308-4|N=10|Linear) is added under the Khan_training_data item in the Experiments navigator.
If you have automatic visualizations enabled in your user preferences, the Classification plot showing training results is displayed. The accuracy of this training was perfect. This can be seen by testing on the training data using the procedure outlined below.
Training Parameters
The kernel type (and it’s associated parameters) are the significant parameter in a SVM. Users should begin by trying to use a linear kernel, and then go to poly and rbf in that order if they have problems correctly classifying their dataset. The degree is probably the most significant parameter for the kernel functions. Users should begin by trying a lower degree (e.g. 2) before moving up to higher degree kernel functions. In some cases, polynomial classifiers can fail to terminate. See Tutorial 6 for details on the committee parameters.
Note: Setting the random seed is neither necessary nor recommended in normal use. In the Create Classifier function, the random seed determines how the samples are divided up into subsets for training the component learners (committee members). The random seed generally only affects predictions for borderline or ambiguous samples, which the committee also helps diagnose.
For a discussion of the general Classify Parameters in this dialog (Learners and Learner Votes Required), see Create Classifier.
It is possible to view the results of the classifier training at this point (see Classifier Plot Training Results), but it is even more informative to go on and test the classifier using data it has not already seen.