|


Performing Agglomerative Hierarchical Clustering
Overview
Agglomerative hierarchical clustering starts with each gene or sample as a single cluster, then in each successive iteration, it merges two clusters together until all genes or samples are in one big cluster.
For further details, see Overview of Agglomerative Hierarchical Clustering.
Actions
1. Click a complete dataset in the Experiments navigator. The item is highlighted.
2. Click the Hierarchical
Clustering toolbar icon ![]() , or select Hierarchical Clustering
from the Clustering menu,
or right-click the item and select Hierarchical
Clustering from the shortcut menu. The Hierarchical
Clustering parameters dialog is displayed.
, or select Hierarchical Clustering
from the Clustering menu,
or right-click the item and select Hierarchical
Clustering from the shortcut menu. The Hierarchical
Clustering parameters dialog is displayed.
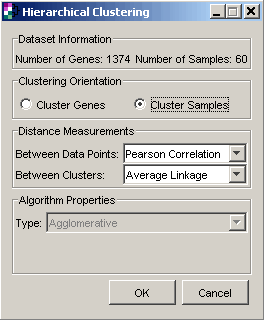
3. Set the parameters.
|
Parameter |
Description |
|
Clustering Orientation |
Cluster by Genes or by Samples. |
|
Distance Measurement Between Data Points |
Type of distance measurement to use to determine how close two data points are to each other. |
|
Distance Measurement Between Clusters |
Type of distance measurement to use to determine how close two clusters are to each other. |
4. Click OK. The Experiment Progress dialog is displayed. It is dynamically updated as the Agglomerative Hierarchical Clustering operation is performed. To cancel the Agglomerative Hierarchical Clustering operation, click the Cancel button.
Upon successful completion, a new item is added under the original item in the Experiments navigator.
Related Topics: